CS377: Database Design - Relational Database Systems (RDS)
Activity Goals
The goals of this activity are:- To define the various components of a typical Relational Database System (RDS)
- To differentiate between the benefits and costs of various indexing structures to improve search performance
- To select between memory and disk structures for backing a database
- To recommend appropriate data structures for efficient storage and search of relational data via indexing
The Activity
Directions
Consider the activity models and answer the questions provided. First reflect on these questions on your own briefly, before discussing and comparing your thoughts with your group. Appoint one member of your group to discuss your findings with the class, and the rest of the group should help that member prepare their response. Answer each question individually from the activity, and compare with your group to prepare for our whole-class discussion. After class, think about the questions in the reflective prompt and respond to those individually in your notebook. Report out on areas of disagreement or items for which you and your group identified alternative approaches. Write down and report out questions you encountered along the way for group discussion.Model 1: Structure of a Relational Database Management (RDBMS) System

Questions
- Some items are stored in memory as well as on disk; how is this reconciled?
- What would happen to the in-memory data if the database system was shut down prior to writing to disk? How might this data be recovered?
Model 2: Indexing
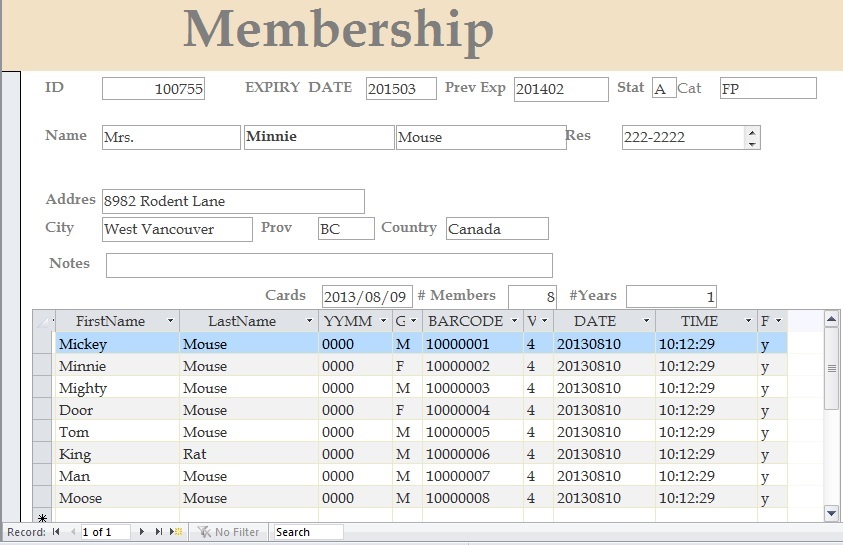

Questions
- What are some strategies you might use to allow a person to look up the location of a record in a database more quickly than by linear search?
- Can you have more than one index on the same table? What might this mean?
- Given a person's name, how might you use a hash table to quickly identify the row that contains the corresponding record?
- How might you change the hash if you wanted to search by date-of-birth rather than by name?
- If the hash table isn't big enough to hold every possible record hash, what could happen? What would the drawback be?
- Given that some indices enable
O(1)constant time lookups, while others areO(log n)logarithmic time lookup with respect to the number of recordsn, what might you speculate is the underlying data structure used to create an index?
Model 3: ACID and BASE, and the CAP Theorem

Questions
- The CAP Theorem specifies the tradeoff between availability, consistency, and partition tolerance. What do you think these mean?
- Why do you think it is not possible to achieve all three items in the CAP Theorem?
- How do the ACID and BASE models appear to balance these tradeoffs?
Relational Database Systems (RDS) serve as a fundamental component in the field of data management. They provide a structured way to organize and store vast amounts of data, ensuring efficient data retrieval and manipulation. RDS utilize tables, which consist of rows and columns, enabling the establishment of relationships between entities.
Key Concepts in RDS
Tables
Tables are the primary structure in relational database systems. They represent entities or concepts and are composed of rows and columns. Each column has a defined data type, specifying the kind of data it can store (e.g., text, numeric, datetime).
Primary Key
A primary key is a column or a set of columns that uniquely identify each record or row in a table. It ensures data integrity by prohibiting duplicate values.
Relationships
RDS make use of relationships to link tables together. The most common relationship types are:
- One-to-One (1:1): Each record in one table is related to exactly one record in another table.
- One-to-Many (1:N): Each record in one table can be related to multiple records in another table.
- Many-to-Many (N:N): Multiple records in one table can be related to multiple records in another table.
Joins
Joins are operations that combine related tables to retrieve data that spans multiple tables. They allow for querying and retrieving information from multiple tables simultaneously.
Indexing
Indexing is the process of creating an index on a specific column in a table. It enhances query performance by enabling faster data retrieval based on indexed columns.
RDS in Python
Python provides several libraries for working with relational databases:
- sqlite3: A built-in Python library for interacting with SQLite databases.
import sqlite3
# Connect to an existing SQLite database or create a new one
conn = sqlite3.connect('database.db')
# Create a cursor object to execute SQL statements
cursor = conn.cursor()
# Execute SQL statements
cursor.execute('CREATE TABLE students (id INTEGER PRIMARY KEY, name TEXT, age INTEGER)')
# Commit changes and close the connection
conn.commit()
conn.close()
- SQLAlchemy: A powerful Python library that provides a SQL toolkit for working with relational databases.
from sqlalchemy import Column, Integer, String, create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
# Define a model
Base = declarative_base()
class Student(Base):
__tablename__ = 'students'
id = Column(Integer, primary_key=True)
name = Column(String)
age = Column(Integer)
# Connect to the database
engine = create_engine('sqlite:///database.db')
Session = sessionmaker(bind=engine)
session = Session()
# Create a new student
new_student = Student(name='John Doe', age=20)
session.add(new_student)
session.commit()
# Retrieve all students
students = session.query(Student).all()
for student in students:
print(student.name, student.age)
# Close the session
session.close()
RDS Theory: ACID and BASE
CAP Theorem
The CAP theorem, also known as Brewer’s theorem, states that it is impossible for a distributed data store to simultaneously provide more than two out of the following three guarantees:
- Consistency: Every read receives the most recent write or an error.
- Availability: Every request receives a response, without guarantee that it contains the most recent write.
- Partition Tolerance: The system continues to operate despite an arbitrary number of messages being dropped (or delayed) by the network between nodes.
In the context of relational databases, this theorem is crucial because it helps in understanding the trade-offs while designing distributed systems. For instance, if a relational database needs to be highly available and partition-tolerant, it might have to compromise on consistency.
ACID Properties
ACID is an acronym that stands for Atomicity, Consistency, Isolation, and Durability. These are a set of properties that guarantee that database transactions are processed reliably.
- Atomicity: This property ensures that all operations within a work unit are completed successfully; otherwise, the transaction is aborted at the failure point, and previous operations are rolled back to their former state.
- Consistency: This property ensures that a transaction brings the database from one valid state to another, maintaining database invariants: any data written to the database must be valid according to all defined rules, including constraints, cascades, triggers, and any combination thereof.
- Isolation: This property ensures that concurrent execution of transactions leaves the database in the same state that would have been obtained if the transactions were executed sequentially.
- Durability: This property ensures that once a transaction has been committed, it will remain committed even in the case of a system failure. This is usually achieved by storing the transaction into a transaction log that can be replayed to recreate the system state right before the failure.
ACID properties are crucial in the context of relational databases as they provide a safe environment where any transaction guarantees the validity of the database state.
BASE Properties
BASE is an acronym that stands for Basically Available, Soft state, Eventually consistent. It is a data system design philosophy that prioritizes availability over consistency.
- Basically Available: This property indicates that the system does guarantee availability, in terms of the CAP theorem.
- Soft state: The state of the system could change over time, even without input. This is because of the eventual consistency model.
- Eventually consistent: The system will become consistent over time, given that the system doesn’t receive input during that time.
In the context of relational databases, BASE properties are often seen as the opposite of ACID properties. While ACID strives for consistency at the end of each transaction, BASE allows for a system to be inconsistent at times, but guarantees that it will eventually achieve a state of consistency.
ACID vs BASE: Trade-offs
Recall that ACID and BASE represent two different approaches to managing data in a distributed system, each with its own trade-offs.
-
ACID (Atomicity, Consistency, Isolation, Durability) properties provide a strict and predictable framework for handling transactions. In the context of the CAP theorem, ACID-compliant databases often prioritize Consistency and Partition Tolerance (CP) over Availability. This means that in the event of a network partition, an ACID-compliant database might become unavailable to ensure that all data remains consistent across the system. The trade-off here is that while data integrity is maintained, the system might not always be accessible.
-
BASE (Basically Available, Soft state, Eventually consistent) properties, on the other hand, prioritize Availability and Partition Tolerance (AP) over Consistency in the CAP theorem. This means that a BASE-compliant system will remain available even in the event of network partitions, but it might not always provide the most recent data. The trade-off here is that while the system is highly available, data consistency is not immediately guaranteed (though it will become consistent over time).
Example Applications
The choice between ACID and BASE often depends on the specific requirements of the application.
-
ACID-compliant databases are often chosen for systems where data consistency is critical. For example, in a banking system, it’s crucial that all transactions are processed reliably and that the data remains consistent at all times. If a customer transfers money from one account to another, the system must ensure that the money is deducted from one account and added to the other in a single, atomic operation. If the system fails at any point, the transaction should be rolled back to ensure data integrity.
-
BASE-compliant databases are often chosen for systems where availability is more important than immediate consistency. For example, in a social media application like Twitter, it’s more important that users are able to post tweets and view content at any time, even if there’s a slight delay in propagating updates across the system. If a user likes a tweet, it’s acceptable if some users see the updated like count a little later, as long as the system remains available and the data eventually becomes consistent.
In conclusion, the choice between ACID and BASE depends on the specific needs of the system. If data consistency is paramount, an ACID-compliant approach might be best. If high availability is more important, a BASE-compliant approach might be more suitable. Understanding the trade-offs between these two approaches can help designers make informed decisions about how to manage data in their systems.
Indexing
We can use hashing to more efficiently index data within an RDS. By looking up a hash table according to its index, we can identify the location of a record in constant O(1) time. In addition to storing the record, we also store the hash table in the datastore. This code uses Python’s built-in pickle module for serialization and deserialization of the Python object structure. For hashing, it uses Python’s built-in hashlib module.
import os
import pickle
import hashlib
class HashIndex:
def __init__(self, file_name):
self.file_name = file_name
self.index = {}
if os.path.exists(self.file_name):
self._load()
def _load(self):
with open(self.file_name, 'rb') as f:
self.index = pickle.load(f)
def _save(self):
with open(self.file_name, 'wb') as f:
pickle.dump(self.index, f)
def add(self, key, value):
hash_key = self._hash(key)
self.index[hash_key] = value
self._save()
def get(self, key):
hash_key = self._hash(key)
return self.index.get(hash_key)
def _hash(self, key):
return hashlib.sha256(key.encode()).hexdigest()
# Usage
index = HashIndex('index.bin')
index.add('key1', 'value1')
print(index.get('key1')) # Outputs: value1
In this example, HashIndex is a class that represents a hash-based index stored in a binary file. The add method adds a key-value pair to the index, and the get method retrieves a value by its key. The _hash method is a helper method that computes a SHA-256 hash of a key. The _load and _save methods are used to load the index from a file and save the index to a file, respectively.