CS377: Database Design - Data Modeling and Schemas
Activity Goals
The goals of this activity are:- To identify use cases appropriate to the relational, network, and hierarchical database model
- To create database schemas in standardized formats
Supplemental Reading
Feel free to visit these resources for supplemental background reading material.The Activity
Directions
Consider the activity models and answer the questions provided. First reflect on these questions on your own briefly, before discussing and comparing your thoughts with your group. Appoint one member of your group to discuss your findings with the class, and the rest of the group should help that member prepare their response. Answer each question individually from the activity, and compare with your group to prepare for our whole-class discussion. After class, think about the questions in the reflective prompt and respond to those individually in your notebook. Report out on areas of disagreement or items for which you and your group identified alternative approaches. Write down and report out questions you encountered along the way for group discussion.Model 1: Network and Hierarchical Data Models
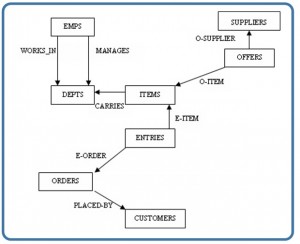
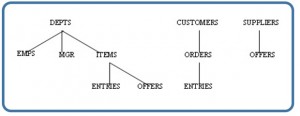
Questions
- What do edges (or vertices) represent in each model?
- Do these edges represent 1:1 or 1:many relationships?
- How might you implement each of these models using the traditional relational database model?
- Sketch a model of the student enrollment tables we made previously in the hierarchical model.
- Design tables and keys to represent the manager-employee hierarchical model.
Model 2: Database Schemas

Questions
- Draw lines between the foreign keys that you find and their primary keys. What do you notice about these lines, with respect to the clusters of tables?
- Which tables need to be modified to add a log message to the database? Do any records need to be modified elsewhere? How might you define the concept of physical data independence based on this idea?
- How might you define logical independence (independence within the schema itself), given our definition of physical independence?
Data Modeling
Data modeling is the process of structuring and organizing data to effectively represent the real-world entities and relationships it represents. A schema is a blueprint or a plan that describes the structure and organization of a database system. This report will explore the fundamentals of data modeling, various types of schemas, and their importance in the context of database design.
Definition
Data modeling is the process of creating a conceptual representation of data objects, their attributes, and the relationships between them. It helps in creating a clear understanding of the data requirements and aids in effective communication among stakeholders.
Types of Data Models
- Conceptual Data Model: This model represents high-level entities, their attributes, and the relationships between them. It focuses on understanding and documenting concepts rather than implementation details.
- Logical Data Model: The logical data model focuses on translating the conceptual model into a more detailed structure that can be implemented in a specific database management system (DBMS). It defines the tables, columns, relationships, and constraints.
- Physical Data Model: The physical data model specifies how the logical data model will be implemented within a specific DBMS. It includes details such as data types, indexes, partitions, and storage details.
Benefits of Data Modeling
- Structural Clarity: Data modeling provides a clear structure for organizing and understanding data, improving the overall quality and consistency of the database.
- Data Integrity: By defining relationships and constraints, data modeling ensures the integrity of the data, preventing inconsistencies and errors.
- Efficient Querying: Well-designed data models enable efficient querying, as they optimize the use of indexes, partitions, and other database features.
- Scalability and Flexibility: Data modeling helps in designing databases that can scale and adapt to changing requirements without major restructuring or data loss.
Implementing Data Models with Python
Python provides several libraries and frameworks that facilitate data modeling and database design. One such popular library is SQLAlchemy. SQLAlchemy is an Object-Relational Mapping (ORM) tool that enables developers to work with databases using Python classes and objects. It provides a high-level, expressive approach to working with databases, making data modeling and schema design more convenient and intuitive.
Here’s a simple example of creating a data model using SQLAlchemy:
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
# Create a database engine
engine = create_engine('sqlite:///mydatabase.db', echo=True)
# Define the base class for data models
Base = declarative_base()
# Define a data model class
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
email = Column(String)
# Create the tables in the database
Base.metadata.create_all(engine)
This example demonstrates the creation of a simple “User” data model with SQLAlchemy, defining the table name, column names, and their data types. The create_all method creates the corresponding table in the database specified by the engine.
Schemas
Definition
A schema is a logical structure that represents the organization and design of a database system. It defines the tables, columns, relationships, constraints, and other elements that constitute the database.
Types of Schemas
- Physical Schema: The physical schema defines how the data is physically stored and organized on disk. It includes details such as file structures, indices, and storage methods.
- Logical Schema: The logical schema represents the structure and organization of data at a higher level of abstraction, independent of the physical storage details. It focuses on the relationships and constraints between tables and provides a conceptual view of the data.
- External Schema: An external schema is a subset of the logical schema, providing a view of the database tailored to the requirements of specific user groups or applications. It defines the tables and columns accessible to the user or application.
Benefits of Schemas
- Data Organization: Schemas provide a structured and organized way to store and access data, enabling efficient data retrieval and management.
- Data Security: Schemas can be used to control access to specific tables or columns, ensuring data security and privacy.
- Data Consistency: By enforcing relationships and constraints, schemas maintain data consistency and integrity across the database.
- Modularity and Scalability: Schemas allow for modular design, where changes can be made to specific schema components without impacting the entire database. This also enables scalability by allowing for distributed and parallel processing.